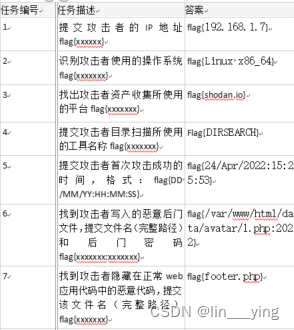
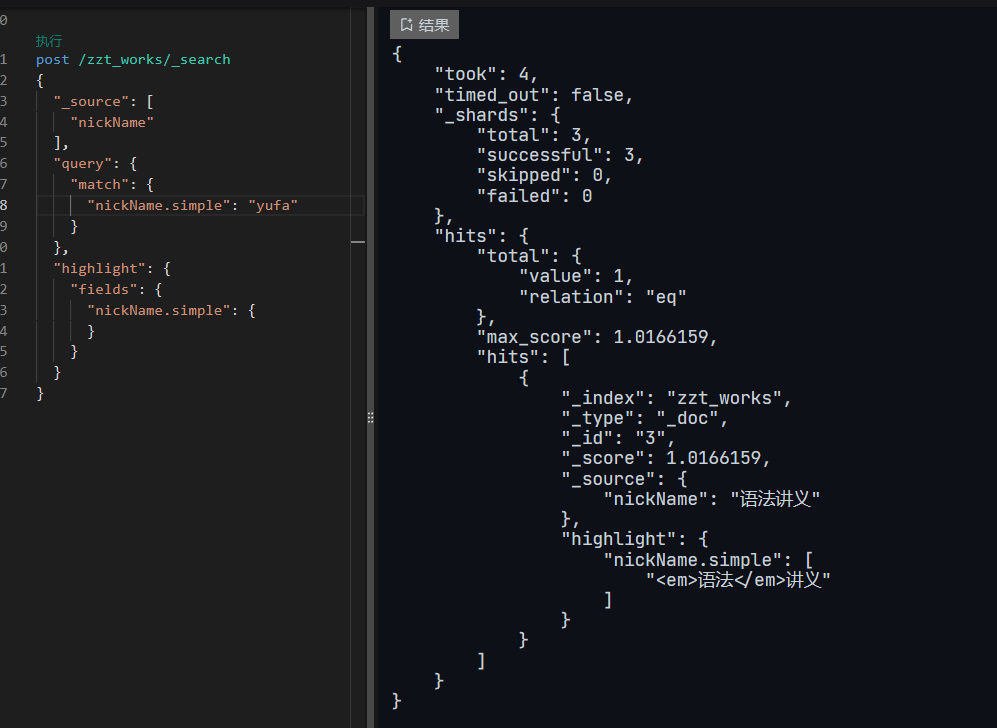
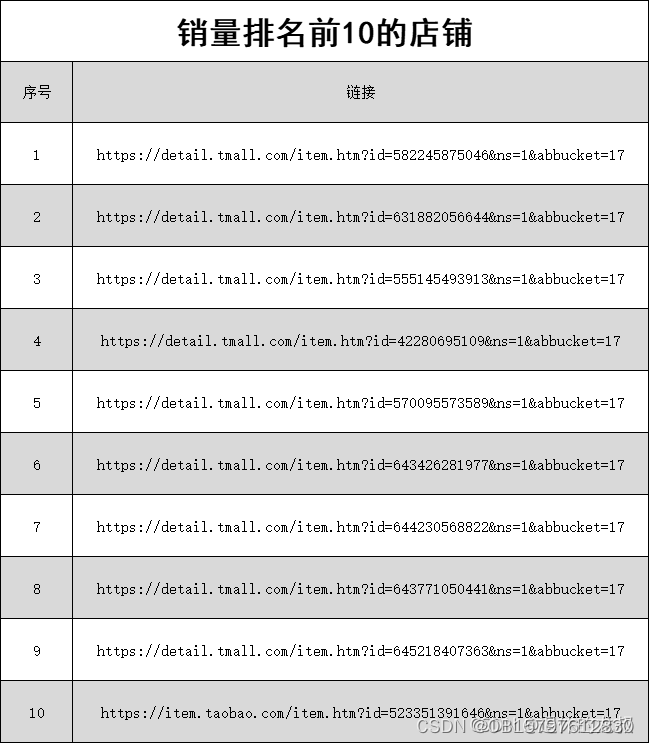
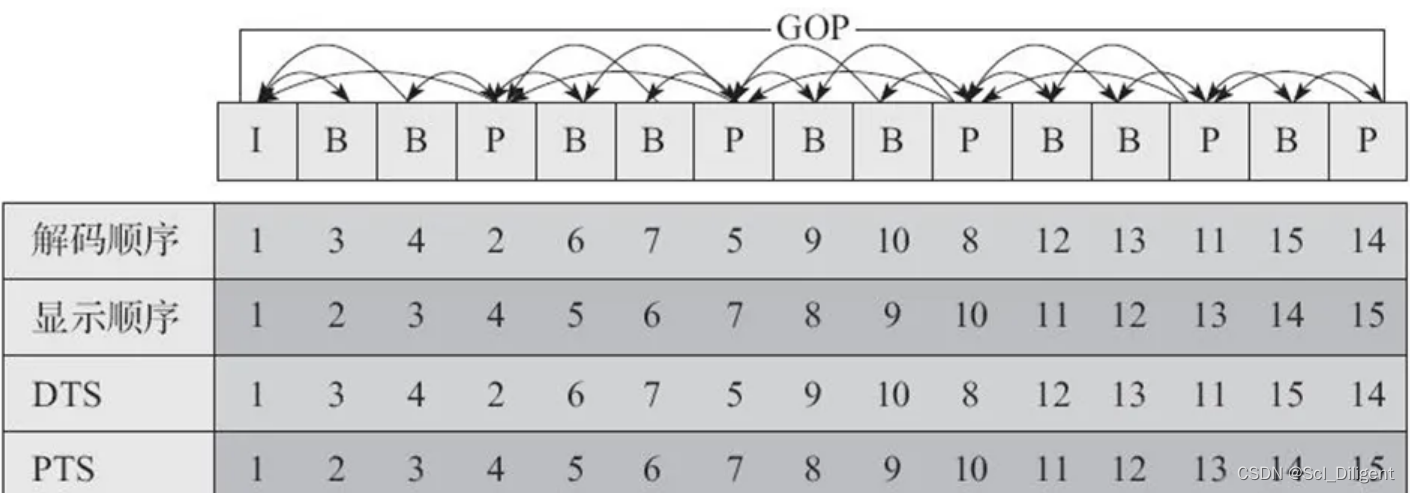
第1关:创建数据集
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing','flippers']
return dataSet, labels
####请在此处输入代码####
myDat, t = createDataSet()
#######################
print(myDat)
第2关:计算数据集的信息熵
from math import log
import operator
def calcShannonEnt(dataSet):
numEntries = len(dataSet) #声明数据集中样本总数
labelCounts = {} #创建字典
for featVec in dataSet: #所有可能分类的数量和发生频率
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2) #log base 2
return shannonEnt
第3关:数据集的划分
def splitDataSet(dataSet, axis, value):
retDataSet = [] #创建列表对象引用数据集,防止由于多次调用而改变元数据集。
####请在此处输入代码####
for i in dataSet:
if i[axis] == value:
t = i[:axis]
t.extend(i[axis + 1:])
retDataSet.append(t)
#######################
return retDataSet
第4关:计算信息增益
from ex03_lib import calcShannonEnt,splitDataSet
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #最后一个元素是当前实例的类别标签。
baseEntropy = calcShannonEnt(dataSet) #计算原始信息熵。
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures): #遍历数据集中所有特征。
featList = [example[i] for example in dataSet]#create a list of all the examples of this feature
uniqueVals = set(featList) #创建唯一的分类标签列表。
newEntropy = 0.0
####请在此处输入代码####
for value in uniqueVals: #遍历当前特征中所有唯一的特征值。
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet) #计算每种划分方式的信息熵。
infoGain = baseEntropy - newEntropy #计算信息增益。
#######################
if (infoGain > bestInfoGain): #将结果与目前所得到的最优划分进行比较。
bestInfoGain = infoGain #如果结果优于当前最优化分特征,则更新划分特征。
bestFeature = i
return bestFeature #返回最优划分的索引值。